Long-horizon problem solving depends on what an agent can remember, inspect, execute, and revise. NotEvolve makes the notebook itself the agent's world model. Instead of evolving only a program file or appending text to a transcript, the system evolves complete notebook branches that contain executable code, natural-language plans, intermediate outputs, plots, summaries, and hidden kernel state.
Why a Notebook?
Evolvable State
A branch is a full notebook state, denoted as Nt(i), rather than a single source file. Selection can preserve whole research trajectories.
Multimodal Memory
Cells store plans, code, text outputs, tables, images, and summaries. The renderer exposes only the useful parts to the LLM context.
Executable Environment
The kernel keeps helper functions, cached data, solver states, and best-known variables alive, so later cells can build on earlier experiments.
How NotEvolve Runs
NotEvolve has an outer loop and an inner loop. The outer loop is a general evolution controller: it receives a population of notebook branches and their scores, then proposes the next population by selection, mutation, recombination, tournament search, MAP-Elites, or another evolution strategy. The inner loop runs one branch for one round.
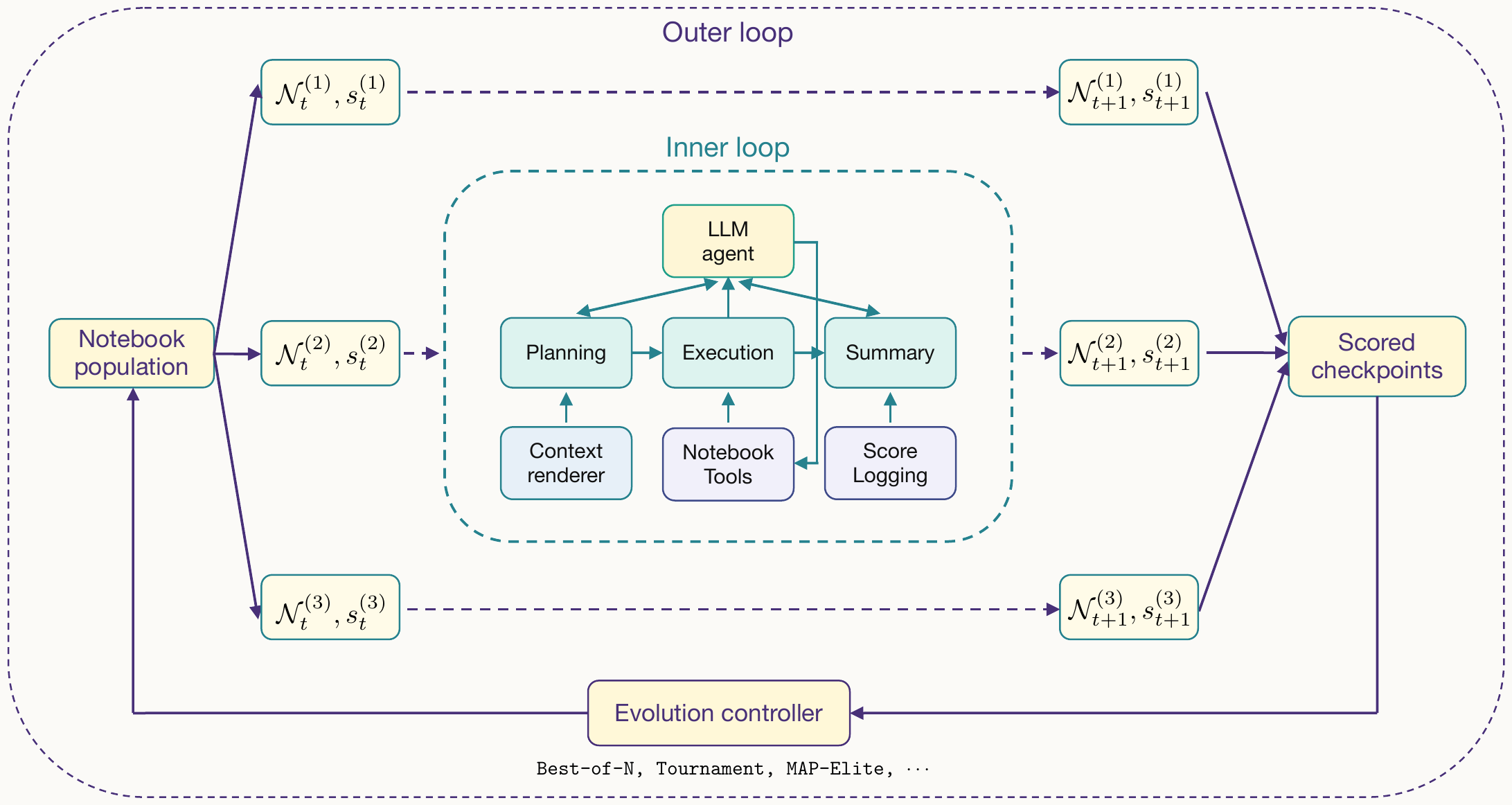
Context Management
A raw Jupyter notebook is a verbose JSON document with execution metadata, widget state, and potentially long cell outputs. NotEvolve instead renders the notebook into a compact text view, exposes only the cells that are useful for the current decision, and lets the agent actively summarize, fold, unfold, and delete cells as the notebook grows.
Render notebook JSON into compact LLM context.
Append new cells, summarize runs, and clip long outputs.
Fold useful history and remove failed branches of work.
(50 lines) baseline()
output: score = 0.8
(50 lines) baseline()
output: score = 0.8
(32 lines) methodA()
output: score = 0.6
(45 lines) methodB()
output: score = 1.0
(45 lines) methodB()
output: score = 1.0
Results
We evaluate NotEvolve across three settings: mathematical optimization with directly evaluable objectives, Terminal Bench software tasks with a local open-weight model, and MLEBench-style Kaggle workflows with long-horizon data and modeling loops.
Mathematical Optimization
Under the same Gemini 3 Flash base model, NotEvolve matches or exceeds AlphaEvolve/OpenEvolve-style baselines on the tested mathematical optimization tasks.
| Problem | AlphaEvolve | OpenEvolve | NotEvolve |
|---|---|---|---|
| Circle Packing ↑ | 2.635 | 2.4672 | 2.635983 |
| Erdos Min-Overlap ↓ | 0.380923 | 0.4334 | 0.38089 |
| Heilbronn Triangle ↑ | 0.03653 | 0.0349 | 0.03653 |
| Min-Max Distribution ↑ | 0.24004706 | 0.2300 | 0.24005088 |
Terminal Bench
We adapt ten Terminal Bench tasks and run them with the same locally served Nemotron-3-Nano-30B model. The notebook harness gives the model persistent executable state, shell outputs, intermediate files, and error-recovery context.
The bare Nemotron model achieves only 33.8% pass rate (27/80 trials), failing entirely on 5 of 10 tasks. With the NotEvolve harness, the same model achieves 100% pass rate on all 10 tasks in a single trial each — often completing tasks faster than the bare model's average across 8 attempts. This demonstrates that the notebook harness can compensate for a weaker base model on practical software engineering tasks requiring multi-step reasoning, tool use, and error recovery.
| Task | Bare Nemotron Pass Rate | Bare Nemotron Avg Time | NotEvolve Pass Rate | NotEvolve Time | Speedup |
|---|---|---|---|---|---|
| hello-world | 8/8 | 41s | 1/1 | 12s | 3.4× |
| csv-to-parquet | 8/8 | 156s | 1/1 | 17s | 9.2× |
| fix-permissions | 8/8 | 45s | 1/1 | 25s | 1.8× |
| extract-safely | 2/8 | 55s | 1/1 | 40s | 1.4× |
| simple-web-scraper | 1/8 | 163s | 1/1 | 51s | 3.2× |
| download-youtube | 0/8 | 311s | 1/1 | 149s | 2.1× |
| vim-terminal-task | 0/8 | 303s | 1/1 | 151s | 2.0× |
| count-dataset-tokens | 0/8 | 358s | 1/1 | 254s | 1.4× |
| oom | 0/8 | 250s | 1/1 | 26s | 9.6× |
| train-fasttext | 0/8 | 639s | 1/1 | 82s | 7.8× |
MLEBench-style Kaggle Tasks
We compare NotEvolve with AIDE, CheetahHarness, and OpenEvolve on public Kaggle-style MLEBench tasks using the same locally hosted Nemotron-120B-Super model. This setting stresses notebook memory: the agent must inspect data, build pipelines, cache intermediate artifacts, recover from errors, and iterate on submissions.
NotEvolve is competitive with CheetahHarness, the strongest realistic code-development baseline, and is best or tied-best on several tasks including random-acts-of-pizza, tps-dec-2021, and dog-breed. The tradeoff is token budget and wall-clock time: NotEvolve exposes rich notebook state to the model, which increases context cost and leads to more compute-intensive pipelines. Stronger context compaction is the key next step.
| Task | Metric | NotEvolve | AIDE | CheetahHarness | OpenEvolve |
|---|---|---|---|---|---|
| random-acts-of-pizza | AUC ↑ | 0.7799 | 0.7746 | 0.7689 | 0.531 |
| nomad2018 | RMSLE ↓ | 0.0621 | 0.0675 | 0.0603 | 0.259 |
| spaceship-titanic | acc ↑ | 0.8149 | 0.7977 | 0.8218 | 0.802 |
| spooky-author | LL ↓ | 0.4164 | 0.5494 | 0.4634 | 0.363 |
| jigsaw-toxic | AUC ↑ | 0.9748 | 0.9748 | 0.9730 | — |
| tps-dec-2021 | acc ↑ | 0.9608 | 0.9405 | 0.8934 | 0.908 |
| tps-may-2022 | acc ↑ | 0.9270 | 0.9041 | 0.9082 | 0.982 |
| dog-breed | LL ↓ | 0.7782 | 0.8275 | 4.1775 | 4.814 |
| nyc-taxi (5.3 GB) | RMSE ↓ | 4.4589 | 5.3568 | 4.6838 | 3.119 |
| dogs-vs-cats (1.2 GB) | LL ↓ | 0.3542 | 0.1213 | 0.6645 | 0.628 |
KernelBench GPU Kernels
KernelBench extends our evaluation to systems optimization. Each task asks an agent to replace a PyTorch workload with a correct and faster GPU kernel, so success requires more than code generation: the agent must compile, test, benchmark, and revise candidate kernels. This makes it a natural stress test for notebook-based memory, since a notebook can preserve candidate kernels, error traces, benchmark outputs, and debugging notes across attempts.
Across 300 trials, NotEvolve achieves higher overall mean speedup than CheetahHarness, 1.096 vs. 0.982, and finds more successful accelerations: 76 vs. 49 trials above 1.0x speedup and 15 vs. 4 trials above 2.0x speedup. The gain is strongest on Level 1, while Level 2 is essentially tied. NotEvolve uses fewer input tokens on average, but more output tokens and slightly higher wall-clock time, so this is not a wall-clock speedup claim. The result suggests that notebook-based state improves speedup discovery overall, but stronger harness engineering is still needed to reduce compile-run-debug overhead.
KernelBench radar
Speedup quality vs. efficiency
Level 1
strongest gainLevel 2
essentially tiedState Matters
The largest gains appear when progress depends on intermediate artifacts: evaluated layouts, shell outputs, trained models, cached data, and recoverable failed attempts.
Cost Tradeoff
The notebook state improves long-horizon behavior, but rich context can be expensive. Better state distillation is a key direction for future versions.
Case Study: Circle Packing
The Circle Packing task asks the agent to place 26 circles inside the unit square and maximize the sum of radii while keeping all circles non-overlapping and within the boundary. The notebook is useful here because the agent can repeatedly score layouts, visualize gaps, keep the best layout in kernel variables, and warm-start new solvers from previous cells.
Current notebook behavior
Grid baseline
A simple grid gives a valid but loose packing.
Executable Scoring
Each candidate is evaluated in the notebook, so the score becomes an immediate signal for the next branch and the next outer-loop selection step.
Visual Diagnosis
Plots reveal empty regions and contact structure that are hard to infer from source code alone.
Warm-start Search
Later cells reuse variables such as the current best centers and radii, then try new local optimizers and relocation moves.
Discussion
These experiments support the main hypothesis of the project: for long-horizon agents, state representation is a core capability. The notebook gives the agent a persistent laboratory where partial solutions, failures, summaries, plots, and live objects remain available to future reasoning steps.
The next challenge is making this state more efficient and robust. Notebooks can accumulate many cells and long outputs, so stronger context distillation, folding policies, and cleanup are needed. Kernel state also needs better checkpointing, replay, dependency tracking, and sandboxing before notebook-state evolution can be deployed broadly across scientific, systems, and machine-learning engineering workloads.